
Trong những năm qua, thuật ngữ Trí tuệ nhân tao, Deep learning (học sâu) đã dần len lỏi vào ngôn ngữ kinh doanh mỗi khi có cuộc hội thoại nào bàn về trí tuệ nhân tạo (AI), dữ liệu lớn (Big Data) và phân tích (Analytics).
Và với lý do chính đáng – đây là một cách tiếp cận đầy hứa hẹn tới AI khi phát triển các hệ thống tự trị, tự học, những thứ đang cách mạng hóa nhiều ngành công nghiệp.
Bài viết này chúng ta sẽ đi tìm hiểu 4 khái niệm chính thường gặp nhất trong thế giới trí tuệ nhân tạo : AI , Machine Learning , Deep Learning và NLP.
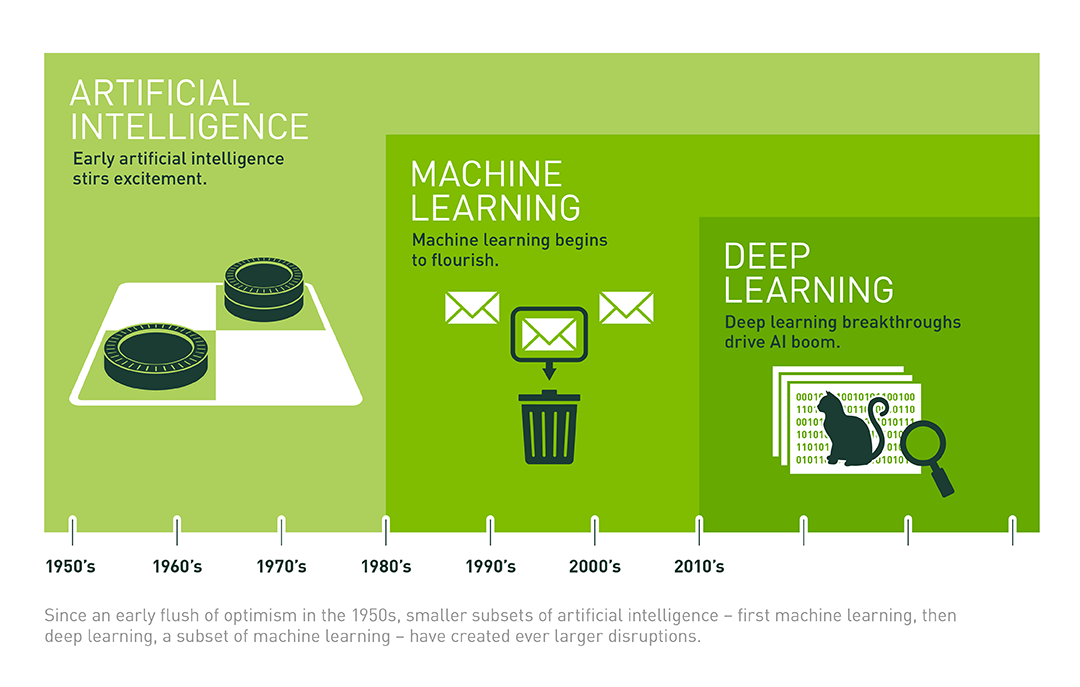
Trí tuệ nhân tạo – trí tuệ con người được mô phỏng bởi máy móc

Trở lại mùa hè năm 1956, ước mơ của những nhà tiên phong về công nghệ bấy giờ là xây dựng các máy móc phức tạp – có đặc điểm giống với trí thông minh con người. Đây là khái niệm mà chúng ta nghĩ là “General AI” – những thiết bị hoàn hảo có tất cả các giác quan của con người (có thể nhiều hơn), có khả năng suy đoán, suy nghĩ như chúng ta.
Có thể bạn đã nhìn thấy nó trong một loạt các bộ phim như friend — C-3PO — and foe — The Terminator. Tuy nhiên, General AI vẫn còn nằm trong các bộ phim và tiểu thuyết khoa học viễn tưởng vì lý do nhân đạo. Chúng ta không thể thực tế nó, hoặc ít nhất là chưa phải lúc này.
Như vậy Trí tuệ nhân tạo là một công nghệ hoặc hệ thống máy tính được thiết kế để hoạt động theo cách mô phỏng cách suy nghĩ của bộ não con người. Thuật ngữ này là một lĩnh vực bao quát của khoa Máy học tính bao gồm một loạt các thể loại, bao gồm xử lý ngôn ngữ tự nhiên, Máy học , học sâu, mạng lưới thần kinh, trừu tượng hóa nội dung, ra quyết định và hơn thế nữa.
AI lần đầu tiên được đặt ra bởi nhà khoa học John McCarthy tại Đại học Dartmouth năm 1956. Điều quan trọng cần nhớ là AI thực sự bao gồm các thuật toán được cung cấp bởi dữ liệu và kết quả hoặc đề xuất mà nó tạo ra hoàn toàn phụ thuộc vào dữ liệu đầu vào.
Dữ liệu càng chính xá, đầu ra càng chính xác . Và ngược lại. Lấy ví dụ, thí nghiệm thất bại của Amazon khi sử dụng AI cho tuyển dụng, đã tạo ra kết quả thiên vị so với phụ nữ do số lượng CV nam trong dữ liệu đào tạo của họ.
Hoặc, thí nghiệm Norman của MIT đã tạo ra một AI hoài nghi, người chỉ nghĩ về cái chết sau khi cung cấp dữ liệu từ một nguồn cấp dữ liệu phụ cụ thể.
Machine learning – Cách tiếp cận để chinh phục trí tuệ nhân tạo
Học máy là một tập hợp con của AI bao gồm ‘đào tạo’ máy móc để ‘học’ từ các bộ dữ liệu, cho phép chúng rút ra những hiểu biết sâu sắc và đưa ra quyết định dự đoán. Nó tự động hóa các nhiệm vụ và tìm ra các mẫu hoặc dị thường, học hỏi từ chúng và tạo ra các quy tắc mới cho lần tiếp theo.

Một trong những lĩnh vực ứng dụng tốt nhất cho Machine learning trong nhiều năm qua là computer vision, mặc dù nó vẫn đòi hỏi rất nhiều kỹ năng code thủ công để có thể hoàn thành công việc.
Mọi người vẫn sẽ viết các lớp phân loại bằng tay như các bộ lọc để chương trình có thể xác định nơi mà một đối tượng bắt đầu và kết thúc.
Phát hiện hình dạng để xác định nếu nó có tám mặt. Một phân loại để nhận dạng các chữ cái “S-T-O-P”. Từ tất cả những ứng dụng phân loại, họ sẽ phát triển các thuật toán để làm cho hình ảnh và “học” khả năng nhận diện dấu hiệu liệu nó có phải là kí hiệu stop hay không? .
Deep learning – Kỹ thuật để hiện thực hóa Machine learning
Deep learning hiện là tập hợp con tiên tiến nhất của Máy học , và do đó, một tập hợp con của AI, dự định đưa máy móc càng gần với mức độ tư duy của con người.
Theo MIT Technology Review, Phần mềm học, theo nghĩa rất thực, để nhận ra các mẫu trong biểu diễn kỹ thuật số của âm thanh, hình ảnh và dữ liệu khác bằng cách tạo ra một mạng lưới thần kinh nhân tạo.
Nhận dạng hình ảnh và công nghệ nhận dạng giọng nói rơi vào học tập sâu.

Lấy hình ảnh mèo ra khỏi video trên YouTube là một trong những đột phá đầu tiên của deep learning
Một phương pháp tiếp cận thuật toán khác từ cộng đồng machine-learning, Artificial Neural Networks, được nhắc đến nhiều thập kỷ qua. Neural Networks được lấy cảm hứng từ sự hiểu biết về sinh học của bộ não loài người – sự liên kết giữa các nơ-ron. Tuy nhiên, không giống như một bộ não sinh học nơi mà bất kỳ nơ-ron nào cũng có thể liên kết với các nơ-ron khác trong một khoảng cách vật lý nhất định, các mạng thần kinh nhân tạo này có các lớp rời rạc, các kết nối, và các hướng truyền dữ liệu.
Chẳng hạn, bạn có thể lấy một hình ảnh, cắt nó thành một nhóm được đặt vào lớp đầu tiên của mạng thần kinh nhân tạo. Trong lớp đầu tiên các nơ-ron cá nhân truyền dữ liệu đến lớp thứ hai. Lớp thứ hai của nơ-ron làm nhiệm vụ của nó, và như vậy, cho đến khi lớp cuối cùng và cho ra sản phẩm cuối cùng.
Mỗi nơ-ron đảm nhiệm một chức năng – làm thế nào để biết chính xác liệu rằng nó có liên quan đến nhiệm vụ đang được thực hiện. Vì vậy, suy nghĩ về điểm dừng là một dấu hiệu. Các thuộc tính của một hình ảnh dấu hiệu “dừng” được cắt nhỏ và được “kiểm tra” bởi các nơ-ron – dạng hình trụ, màu đỏ của các động cơ cháy, các chữ cái đặc trưng, kích thước biển báo giao thông, và sự chuyển động hoặc sự thiếu hụt của nó.
Nhiệm vụ của mạng thần kinh là để kết luận liệu đây có phải là dấu hiệu dừng hay không. Nó đi kèm với một “vector xác suất”. Trong ví dụ của chúng ta, hệ thống có thể xác định chắc chắn đến 86% một dấu hiệu dừng, 7% rằng đó là một dấu hiệu giới hạn tốc độ, và 5% còn lại là một con diều bị mắc kẹt trong cây,( hoặc cái gì đó tương tự) vv … và kiến trúc mạng sau đó sẽ thông báo đến mạng nơron cho dù đó là đúng hay sai.
Thậm chí ví dụ này cũng là một sự tiến bộ, bởi vì mạng lưới thần kinh đã có thể làm được tất cả nhưng bị xa lánh bởi cộng đồng nghiên cứu về AI. Nó đã có mặt từ những ngày đầu tiên của AI, và tạo ra rất ít sản phẩm “trí tuệ”. Vấn đề là ngay cả những mạng nơ-ron cơ bản nhất cũng có tính toán rất cao, nó không phải là cách tiếp cận thực tiễn. Tuy nhiên, một nhóm nghiên cứu nhỏ do Geoffrey Hinton thuộc trường đại học Toronto đứng đầu, cuối cùng đã parallelizing các thuật toán cho siêu máy tính để chạy và chứng minh khái niệm, nhưng nó không chính xác cho đến khi GPU được triển khai .
Nếu chúng ta quay trở lại ví dụ “ký hiệu dừng”, rất có thể là khi mạng đang được điều chỉnh hoặc được “đào tạo” thì sẽ có câu trả lời sai – rất nhiều. Những gì nó cần là luyện tập. Nó cần phải nhìn thấy hàng trăm ngàn, thậm chí hàng triệu hình ảnh, cho đến khi trọng lượng của đầu vào nơ-ron được điều chỉnh chính xác đến mức nó có được câu trả lời ngay trong thực tế mọi lúc – sương mù hoặc không có sương mù, nắng hoặc mưa. Vào thời điểm đó mạng thần kinh đã tự dạy cho nó một dấu hiệu dừng như thế nào; Hoặc khuôn mặt của mẹ bạn trong trường hợp của Facebook. Hay một con mèo, đó là điều mà Andrew Ng đã làm trong năm 2012 tại Google.
Xử lý ngôn ngữ tự nhiên (NLP)
Xử lý ngôn ngữ tự nhiên (NLP) là một yếu tố của việc học sâu liên quan đến việc dịch văn bản hoặc cách nói của con người để máy tính có thể phân loại và hiểu ý nghĩa của nó. NLP là một ví dụ về làm giàu dữ liệu. Sử dụng công nghệ này, AI có thể trích xuất các yếu tố từ một phần dữ liệu – ví dụ: tên công ty, ngày, sự kiện (ví dụ: mua lại), liên kết và tình cảm.
Nó cũng cho phép AI phân tích các dạng dữ liệu phi cấu trúc khác – từ video, đến tìm kiếm.
Kết hợp với phân tích ngữ nghĩa, NLP AI cũng có thể xem xét ngữ cảnh để xác định ý nghĩa từ một câu hoặc điểm dữ liệu.
Những đổi mới của NLP đang giúp chúng ta cải thiện tìm kiếm theo cách sử dụng ngôn ngữ gần giống với cách suy nghĩ của con người. Kết quả là, nó giúp cải thiện tìm kiếm dự đoán, gợi ý các từ hoặc câu trong văn bản và email, cho phép nhận dạng giọng nói, dịch thuật và nhiều hơn nữa.
Cuộc cách mạng AI chính thức ở đây. Để duy trì tính cạnh tranh khi chúng ta tiến tới những tiến bộ kỹ thuật hơn nữa, điều quan trọng là mọi công ty đều nắm bắt công nghệ mới này và thực hiện thay đổi từ trên xuống.
Những người có thể hiểu và nói về các thuật ngữ này sẽ thấy mình có lợi thế khi công nghệ tiếp tục phát triển.
tác giả : Marcel Deer