
















Tăng tốc bằng phần cứng trong lĩnh vực xử lý dữ liệu không phải là điều mới mẻ và đã có một lịch sử lâu dài. Tuy nhiên gần đây sự trỗi dậy của công nghệ Edge AI đã làm cho lĩnh vực này sôi động trở nên bao giờ hết.
Hồi còn đi học, chúng ta đã trang bị hệ thống 286 12MHz của chúng ta với coprocessor (bộ đồng xử lý, bộ xử lý phụ) có 80287 đơn vị FPU (Floating Point Unit), chạy ở mức 4,7 MHz.
Không lâu sau, đơn vị xử lý FPU này đã được tích hợp thẳng vào CPU, giảm nhu cầu về bộ đồng xử lý bên ngoài cho các hoạt động toán học. Tuy nhiên, bộ đồng xử lý thực sự đã tồn tại lâu hơn.
Bạn có biết đến GPU mà thiết bạn đang sử dụng để đọc bài viết này? DSP trong điện thoại di động của bạn? Card âm thanh? Chúng đều là các coprocessor, và có một lý do chúng vẫn tồn tại xung quanh chúng ta ngày nay.
CPU của bạn không thể làm mọi thứ
Chính xác là nó không thể! Mẫu bán dẫn cho kiến trúc Intel x86 (thừa kế của kiến trúc 8086 và 80286) thực tế đã quá phức tạp. Thêm các hoạt động bổ sung vào kiến trúc x86 sẽ chẳng đem lại thêm lợi ích gì, ở mức mà nó không đáng để đánh đổi theo Rick Merrit của EETimes.
Trên thực tế, GlobalFoundries, một trong những nhà sản xuất chip silicon lớn nhất đã tuyên bố từ bỏ kế hoạch cho chip 7nm . Nó không còn đáng để thực hiện nữa.

Intel Haswell-EP Xeon E5 2626 V3 ProcessorTại sao đó lại là một vấn đề? Mỗi core của bộ xử lý trong kiến trúc x86 làm rất nhiều thứ khác nhau, nó đã khiến các lập trình viên tự mãn. Không phải lo lắng về việc viết phần mềm tồi – bộ xử lý sẽ đảm bảo cho phần mềm chạy nhanh!
Tất nhiên, Intel đã hiểu rõ điều này vào đầu những năm 2000. Họ đã cố gắng kết thúc kiến trúc x86 bằng dự án Itanium, một bộ xử lý được thiết kế cho điện toán 64bit. Tuy nhiên, AMD đã có một kế hoạch khác và phát hành bộ xử lý x86 có khả năng 64bit, cản trở các kế hoạch của Intel. Và đó là lý do chúng ta đã nhận được một mớ hỗn độn này.
Chuyển hướng sang multi-core
Cách duy nhất để có được nhiều đơn vị oomph hơn từ CPU là mở rộng chúng ra. Đó là lý do tại sao các CPU ngày nay hầu như luôn có nhiều core. Chúng có từ 2 đến 28 core cho các bộ xử lý máy chủ cao cấp hơn, chẳng hạn như dòng Intel Xeon.
Hệ thống pipeline và vector hóa thông minh, bộ nhớ đệm và một số hệ thống phức tạp khác được tìm thấy trong kiến trúc x86 cho phép sử dụng khá tốt các thiết bị điện tử thu nhỏ. Một số tác vụ có thể chạy theo nhóm và bộ xử lý thậm chí có thể dự đoán chính xác các hành động tiếp theo là gì, trước khi chúng xảy ra. Tuy nhiên, như SmartIndustryVN đã đề cập trước đây – những bộ xử lý này đã quá phức tạp.
Các kiến trúc khác thật ra vẫn đang tồn tại. ARM, mà bạn có thể tìm thấy trong rất nhiều thiết bị, từ bộ sạc pin cho đến điện thoại và thậm chí cả chiếc xe hơi của bạn – có một tập lệnh rút gọn, còn được gọi là RISC (Reduced Instruction Set Computer).
IBM đã đi theo con đường RISC. Bộ xử lý RISC có các core đơn giản hơn nhiều, không thể làm được nhiều như các core CPU phức tạp hơn. Phần mềm phải được viết riêng để hỗ trợ multi-core và hưởng lợi từ các loại vi xử lý này.
Hiện tại thì x86 vẫn sẽ được dùng đến trong nhiều năm tiếp. Có thể là 10, 15 năm nữa, nhưng x86 sẽ biến mất.
Nếu bạn muốn tìm hiểu thêm về những gì Intel đang làm để cho phép xử lý song song, hãy đọc Câu chuyện về ISPC, về Trình biên dịch Intel SPMD: https://pharr.org/matt/blog/2018/04/18/ispc-origins.html
Và bây giờ là GPU và GPGPU
Graphic Processing Unit (GPU – Đơn vị xử lý đồ họa) thực ra cũng không mới mẻ gì. Thuật ngữ này đã được sử dụng ít nhất từ năm 1986 , nhưng từng có xu hướng tập trung tuyệt đối vào đồ họa. Chiếc card đầu tiên của NVIDIA được bán trên thị trường dưới cái tên “GPU” đó là card GeForce 256, ra mắt năm 1999. Tuy nhiên, với General Purpose GPU (GPGPU) thực sự chỉ bắt đầu xuất hiện vào khoảng năm 2007, khi NVIDIA và ATI (nay là AMD) bắt đầu trang bị card đồ họa 3D của họ với năng lực xử lý ngày càng cao, VD như Unified Pixel Shader. Các tính năng này được định hướng để thực hiện các phép toán như nhân ma trận, Fast Fourier Transform, phép chuyển đổi sóng,…

Truy cập vào các tính năng này đồng nghĩa với việc các cấu trúc lập trình mới phải được phát hành. Vì vậy, vào năm 2008, Apple đã bắt đầu phát triển OpenCL. Đến cuối năm 2009, nó đã được AMD, IBM, Qualcom, Intel và thậm chí cả NVIDIA chấp nhận. AMD quyết định hỗ trợ OpenCL rộng rãi, thay vì bộ framework “Close to Metal” của họ.

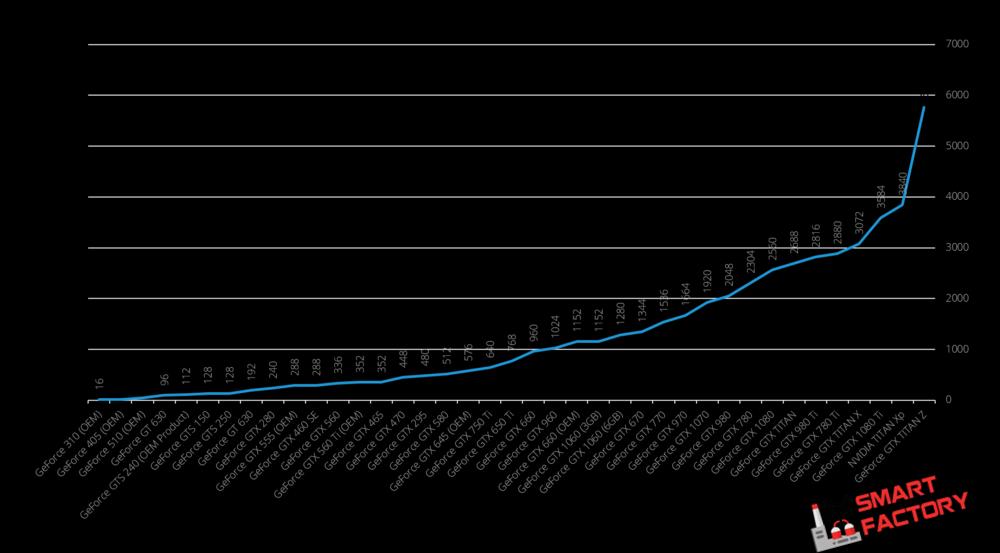
Tại sao chúng ta không thay thế CPU bằng GPU?
Không phải tất cả các ứng dụng đều phù hợp với GPU. GPU chủ yếu hữu ích nếu:
- Các hành động được lặp đi lặp lại
- Các hành động chủ yếu là độc lập (không dựa vào nhau)
- Các hành động nặng về xử lý tính toán thuần túy
GPU đã có một số ứng dụng thú vị ngoài lĩnh vực đồ họa (và tiền ảo – crypto currency). Ngày nay, GPU được thấy nhiều trong các dự án xử lý dữ liệu. Chúng có thể được sử dụng như một phần của đường ống xử lý dữ liệu – data processing pipeline, để chạy các mô hình Machine Learning chạy trên đó, như một phần của hệ thống cơ sở dữ liệu quan hệ được tăng tốc bằng phần cứng, hoặc chỉ để kết xuất kết quả một cách nhanh chóng.
Chúng ta hãy xem ba trong số các lĩnh vực chính mà GPU có thể hỗ trợ trong data processing pipeline:
GPU để xử lý luồng (Stream)
Các giải pháp xử lý luồng mới, như Công cụ Plasma của FASTDATA.io . Hiện có thể tận dụng GPU để xử lý dữ liệu luồng vào và ra khỏi cơ sở dữ liệu (có GPU hoặc không). Công cụ này có thể được sử dụng để thực hiện phân tích và / hoặc chuyển đổi dữ liệu phát trực tuyến trên GPU.
Đối thủ cạnh tranh chính với công cụ của FASTDATA là Spark hỗ trợ GPU, như một tiện ích add-on nguồn mở từ IBM.
GPU Database cho các hoạt động phân tích
Thực tế tất cả các GPU Database đều được xây dựng có mục đích cho việc phân tích.
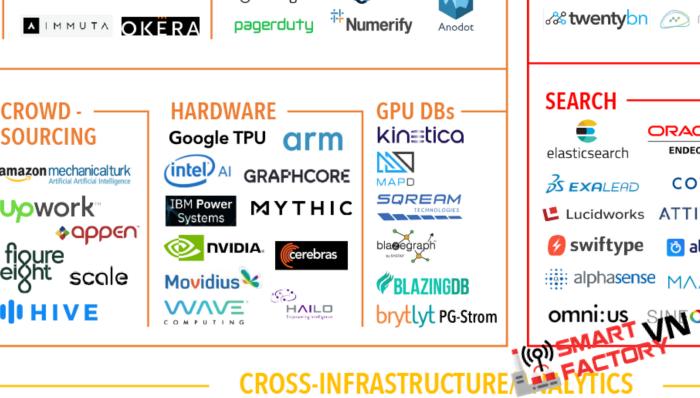
Đã có một số cái tên trong lĩnh vực GPU Database, mỗi cái có lợi thế riêng của nó:
- OmniSci (trước đây là MapD) – Cơ sở dữ liệu GPU in-memory cho các use-case liên quan đến không gian địa lý
- SQream DB – GPU data warehouse cho các tập dữ liệu “lớn hơn RAM”
- BlazedDB – Cơ sở dữ liệu GPU dựa trên Parquet
- Kinetica – Cơ sở dữ liệu GPU in-memory
- HeteroDB – Plugin Postgres, dựa trên UDF để truy cập nhanh vào NVMe
- Brytlyt – Plugin Postgres để tính toán in-memory
- Blazegraph – Cơ sở dữ liệu đồ thị
GPU cho Machine Learning – Machine Learning
Machine Learning có xu hướng rất phù hợp với kiến trúc GPU. Nó không chỉ là vì mức độ song song cao, và khả năng tính toán nhân ma trận. Một phần lớn của lý do thực sự là băng thông bộ nhớ đề cập ở trên.
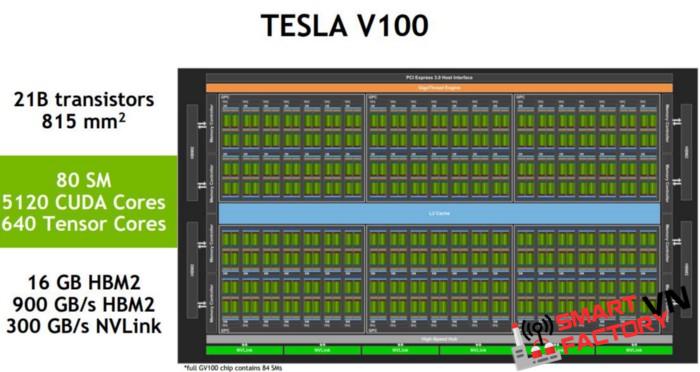
GPU hy sinh độ trễ với tốc độ xung nhịp chậm hơn, để có được thông lượng cao hơn trên mỗi chu kỳ xung nhịp.
Hiện đã có rất nhiều framework hỗ trợ GPU cho machine learning:
- TensorFlow
- CUBLAS
- Caffein
- Theano
- Torch7
- cuDNN
- MATLAB
- cxxnet / mxnet
- Deeplearning4j
- Keras
- Mathematica
và còn rất nhiều framework khác.
Không chỉ có GPU – ASIC, FPGA và những loại phần cứng đặc biệt khác
Mặc dù CPU và GPU mang tính đa mục đích, có một số lựa chọn thay thế khác trong phần cứng, bên cạnh đó là sự đánh đổi.

Phần trên chúng ta đã thảo luận về CPU và GPU, bây giờ hãy làm rõ hơn về các GPU và ASIC cụ thể.
FPGA
Field-Programmable Gate Array (FPGA) là một con chip có khả năng tái lập trình, với hiệu năng cực cao. Chúng rất phổ biến cho các thiết bị mẫu (prototyping) và thiết bị chuyên dụng. Chúng chứa một loạt các khối logic lập trình được và một hệ thống phân cấp các kết nối có thể cấu hình lại.
Vì các FPGAs có thể lập trình được, chúng có thể được thay đổi sau khi sản xuất, nhưng không phải dành cho bất kỳ ai. Chúng cung cấp hiệu năng cao, nhưng chi phí thực hiện đắt đỏ – đó là lý do tại sao chúng vẫn chủ yếu hiện diện ở các thiết bị cấp thấp. Bạn có thể tìm thấy FPGA trong các thiết bị y tế, xe hơi, thiết bị chuyên dụng, v.v…
Các FPGAs cung cấp băng thông bộ nhớ cao hơn, tiêu thụ điện năng thấp hơn CPU (và GPU), nhưng chúng có thể trở nên khó khăn với các tính toán dấu phẩy động và cũng khó làm việc. Trên thực tế, chúng khá khó lập trình, mặc dù các công cụ gần đây như OpenCL cho FPGA đã có.
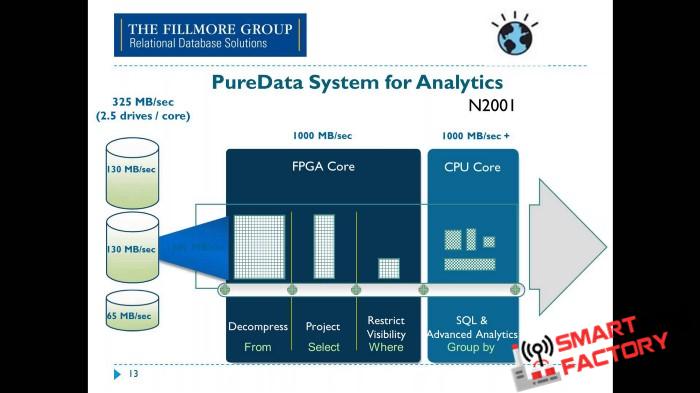
Trong phân tích dữ liệu, các FPGAs phù hợp cho các tác vụ lặp lại đơn giản. Chúng được tìm thấy trong các nền tảng hiện đại như Dự án Brainwave của Microsoft , Trình tăng tốc cơ sở dữ liệu Swarm64 cho Postgres , Trình tăng tốc trung tâm dữ liệu Xilinx Alveo và các thiết bị như Ryft . Một trong những cách sử dụng nổi tiếng nhất của các FPGAs trong lĩnh vực phân tích là Netezza của IBM , mặc dù khía cạnh FPGA của Netezza dường như đã bị bỏ rơi.
Cuối cùng, Netezza đã kết thúc như một phần của IBM PureData và các thành phần FPGA được sử dụng chủ yếu cho các hoạt động cụ thể sẽ được hưởng lợi từ các FPGA như giải nén và chuyển đổi. Các hoạt động khác vẫn sử dụng CPU.
ASIC
Application-Specific Integrated Circuits (ASIC) là giải pháp nhanh nhất cho các hoạt động tốc độ cao, ở cấp độ silicon. Vì những con chip này được tùy biến cao, chúng có thể mang lại hiệu suất tốt nhất với chi phí tối thiểu.
ASIC thường được tìm thấy dưới dạng bộ xử lý tín hiệu số (DSP) – trong xử lý âm thanh, video encoding, networking cùng các ứng dụng khác. Các ứng dụng này chủ yếu có trong các thiết bị sản xuất hàng loạt như máy ảnh, điện thoại di động, bộ định tuyến không dây – wireless router, v.v…
Do chi phí đầu tư và thời gian cao để tạo ASIC tùy chỉnh, chúng cũng là lựa chọn tốn kém nhất. Chúng thực sự là lựa chọn rẻ hơn nếu bạn có kế hoạch sản xuất hàng triệu trong số chúng, nhưng với khối lượng nhỏ hơn, chúng rất khó để làm được. Vì lý do đó, chúng ít được thấy trong lĩnh vực phân tích hoặc xử lý dữ liệu.
So sánh sự đánh đổi
Dưới đây là tóm tắt về các bộ xử lý khác nhau và sự đánh đổi của chúng:
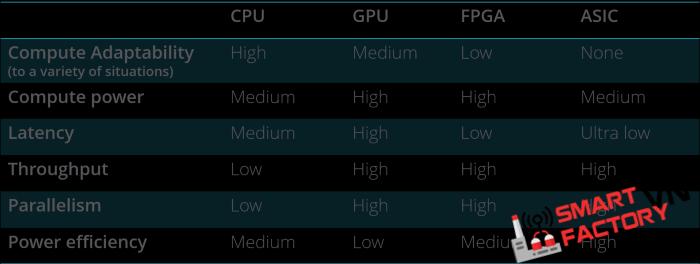
Tương lai của lĩnh vực xử lý dữ liệu tăng tốc bằng phần cứng
Tương lai là sự đa dạng về phần cứng, nhưng không phải tất cả các coprocessor đều phù hợp cho mọi tác vụ.
- Nhiệm vụ của CPU: Giữ cho các chương trình và code tiêu chuẩn, tuần tự chạy được.
- Nhiệm vụ của Coprocessor: Chạy chương trình song song thông lượng cao.
- CPU + Coprocessor: Tăng thông lượng của các chương trình chạy song song.
Rõ ràng là kiến trúc CPU x86 sẽ không tồn tại mãi mãi. Nó chỉ đơn giản là không bền vững trong thời gian dài. Nó không tiến lên với cùng tốc độ với khối lượng công việc dữ liệu hiện đại.
Vì không bị ràng buộc với khả năng tương thích ngược, GPU đang tiến nhanh hơn nhiều. Các workload của dữ liệu hiện đại rất đa dạng, thay đổi, phát triển và di chuyển rất nhanh. GPU và các ứng dụng xử lý dữ liệu được tăng tốc bởi phần cứng khác đang ngày càng phổ biến, với một số thành công đáng chú ý trong lĩnh vực machine learning và data warehousing.
Kết luận
SmartIndustryVN tin rằng việc xử lý dữ liệu tăng tốc phần cứng vẫn còn ở giai đoạn sơ khai, nhưng có tiềm năng trở nên phổ biến hơn, vì các công nghệ hỗ trợ tăng tốc bằng phần cứng tiếp tục có những bước tiến trong kiến trúc CPU ngày nay.






















