










Khái niệm máy học – Machine Learning ngày càng được hiểu rõ hơn khi chúng ta ngày càng tương tác với nó mỗi ngày. Từ các đề xuất của Netflix và Amazon, đến nhận dạng giọng nói Siri và Cortana, đến tính toán thời gian di chuyển trên Google Maps, tất cả chúng ta đều trở nên quen thuộc hơn với công nghệ máy học – Machine Learning — ngay cả khi chúng ta chưa nhận ra điều đó.
Tuy nhiên, việc áp dụng máy học – Machine Learning trong công nghiệp lại là một câu chuyện khác. Mặc dù một số công ty đang làm điều đó, nhưng nó gần như không phổ biến như các ứng dụng hướng đến người tiêu dùng được đề cập ở trên. Và đó là điều đã khiến bài thuyết trình của Kathy Applebaum và Kevin McClusky về Inductive Automation trong Hội nghị Cộng đồng Đánh lửa 2018 trở nên thú vị. Trong phần trình bày của mình, họ giải thích các nhánh chính của máy học – Machine Learning , các loại thuật toán khác nhau được áp dụng và — quan trọng nhất — người dùng công nghiệp có thể Triển khai những bước nào để bắt đầu sử dụng máy học – Machine Learning trong cơ sở của họ.
Nhìn vào thực trạng sử dụng máy học trong ngành công nghiệp ngày nay, Applebaum cho biết bảo trì dự đoán là ứng dụng chính của công nghệ, theo sau là kiểm soát chất lượng, dự báo nhu cầu và đào tạo robot.
Với mối quan tâm rõ ràng và ngày càng tăng đối với máy học – Machine Learning cho các ứng dụng công nghiệp, McClusky chỉ ra rằng phần mềm Ignition IIoT Platform của Inductive Automation hiện có thể được áp dụng tại đây.
Với việc phát hành Ignition IIoT Platform 8.1 vào tháng 5 vừa qua, các thư viện của Ignition IIoT Platform hiện chứa các thuật toán máy học bao gồm nhiều trường hợp sử dụng.
Các loại máy học
Applebaum cho biết điều quan trọng đầu tiên là phải hiểu rằng có ba loại công nghệ chính được gọi là máy học — và không thiếu các tranh luận về sự trùng lặp giữa ba loại này. Ba loại là:
Bạn có thể thích



- Applebaum cho biết Analytics là khám phá kiến thức. “Bạn có thể đã Triển khai phân tích mô tả (tức là chạy báo cáo từ cơ sở dữ liệu). Phân tích chẩn đoán thêm thành phần ‘tại sao’ vào phân tích mô tả để xác định nguyên nhân của sự cố (ví dụ: Tại sao máy bị hỏng?). Phân tích dự đoán xem xét những gì có thể xảy ra trong tương lai và thường không cụ thể lắm, nhưng dựa trên những gì đã xảy ra trước đó. Cuối cùng, phân tích mô tả được xây dựng dựa trên phân tích dự đoán bằng cách đề xuất bước tiếp theo để giải quyết vấn đề ”.
- Bản thân máy học đề cập đến việc sử dụng dữ liệu tự động để học hỏi và cải thiện từ kinh nghiệm.
- Applebaum cho biết trí thông minh nhân tạo bao gồm các nhiệm vụ tính toán mô phỏng trí thông minh của con người.
Thuật toán
Để minh họa cách các thuật toán khác nhau hoạt động để cho phép máy học – Machine Learning ở bất kỳ biến thể nào trong ba biến thể của nó, McClusky đã bắt đầu bằng cách chỉ ra cách ứng dụng máy học – Machine Learning của Ignition IIoT Platform có thể được sử dụng để nhóm các điểm dữ liệu khác nhau lại với nhau. Đối với cuộc trình diễn này, ông đã sử dụng các phép đo dữ liệu chất lượng (chẳng hạn như nhiệt độ và độ ẩm) từ các phần riêng lẻ của quy trình sản xuất.
Bằng cách hiển thị những dữ liệu này trên biểu đồ trong Ignition IIoT Platform , McClusky đã chỉ ra cách người dùng có thể xem dữ liệu từ nhiều khía cạnh trong không gian 2D. Ông nói: “Ignition IIoT Platform phân loại dữ liệu đến từ các cảm biến để sử dụng trong các so sánh đồ họa để bạn có thể thấy mỗi nhóm [dữ liệu] hoạt động như thế nào so với nhau.
Thuật toán máy học – Machine Learning được McClusky sử dụng trong ví dụ này được gọi là K-mean, phân cụm các điểm dữ liệu. “K-mean không biết các danh mục đại diện cho điều gì, nó chỉ tính toán các trung tâm bằng cách tìm ra vị trí của mỗi điểm dữ liệu và cách chúng cách xa nhau,” ông giải thích thêm.
Khả năng này làm cho K-mean tốt cho việc phân loại dữ liệu để phân tích lỗi. Ví dụ: khi một bộ phận mới được đưa vào sản xuất, bạn có thể sử dụng dữ liệu của nó để xem nó có phù hợp với các thông số ‘chất lượng tốt’ đã thiết lập hay không để xác định xem bộ phận đó có đạt yêu cầu phân tích thêm hay không.
Một loại thuật toán máy học – Machine Learning khác được gọi là cây quyết định. Applebaum cho biết thuật toán này rất mạnh mẽ vì nó có thể hướng dẫn bạn từng bước xác định danh mục hoặc công thức cho dữ liệu. Cây quyết định rất hữu ích cho việc bảo trì dự đoán vì bạn có thể sử dụng chúng để xem các quyết định được đưa ra như thế nào. Ngoài ra, bạn có thể sử dụng nó kết hợp với các thuật toán khác.
Phân tích hồi quy là một thuật toán máy học – Machine Learning có thể được sử dụng để điều chỉnh quy trình và dự báo sản xuất. McClusky nói: “Để điều chỉnh quy trình, sử dụng phân tích hồi quy có thể Triển khai một quy trình thủ công và hệ thống tạo ra các điểm đặt được đề xuất [cho ứng dụng thủ công] hoặc đưa các điểm đặt vào thẳng PLC. “Bạn thậm chí có thể sử dụng điều này để kiểm soát quy trình nâng cao để điều chỉnh liên tục.”
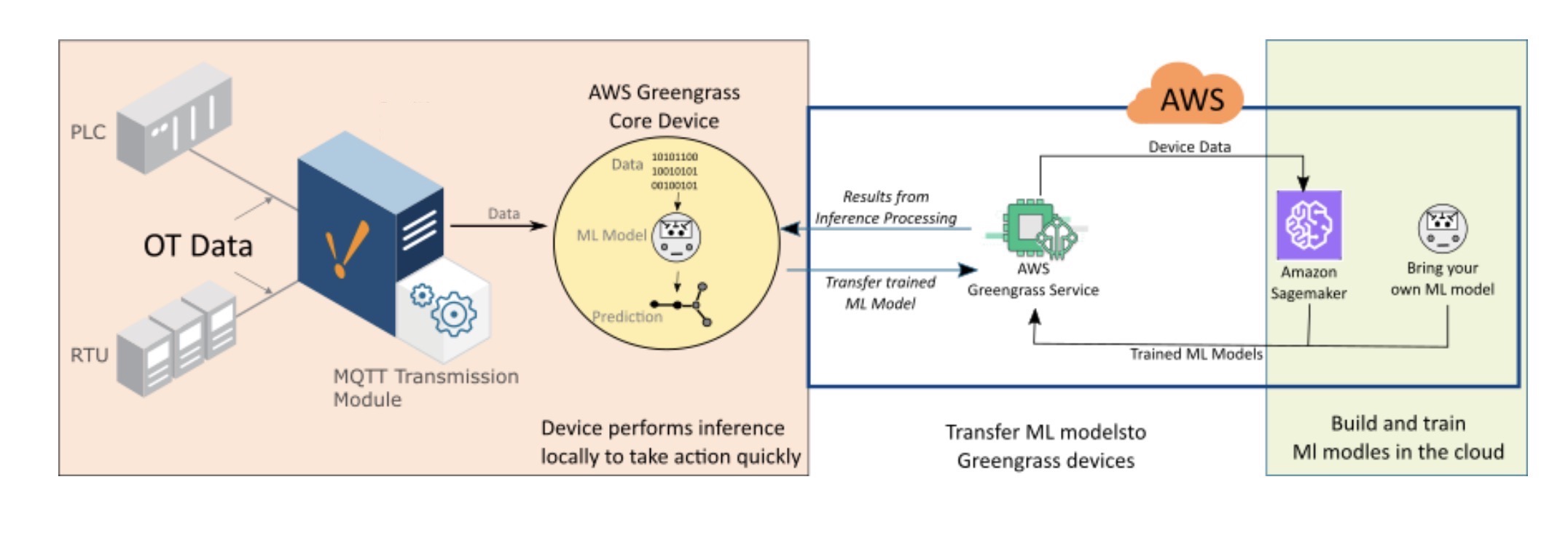
Ông nói thêm rằng phân tích hồi quy có thể được sử dụng để dự báo sản xuất dựa trên tập hợp các biến hiện tại (tức là bất kỳ điểm dữ liệu nào) để xác định, ví dụ, những gì sẽ được sản xuất trên một dây chuyền hoặc tổng thể vào cuối ca làm việc. “Các dự báo dài hạn hơn dựa trên kinh nghiệm trong quá khứ cho tất cả các biến số cũng có thể được Triển khai , chẳng hạn như: Tình hình sản xuất trong một tuần hoặc một tháng kể từ bây giờ như thế nào? Bạn thậm chí có thể nhập các biến từ các hệ thống khác, như SAP. Đối với máy học – Machine Learning [các ứng dụng của phân tích hồi quy], bạn càng sử dụng nhiều biến thì kết quả của bạn càng tốt — tất nhiên, với điều kiện là dữ liệu tốt để bắt đầu, ”ông nói.
Applebaum cho biết các thuật toán mạng thần kinh mô phỏng cách chúng ta nghĩ bộ não của mình hoạt động. Một cách mà mạng nơ-ron thường được sử dụng trong công nghiệp là hệ thống thị giác. Với mạng nơ-ron, bạn có thể xem xét các mục cụ thể trong các dòng hoặc quy trình và sử dụng các cảm biến hiện có để suy ra dữ liệu [từ các khu vực đó] nhằm đơn giản hóa quy trình.
Đề cập đến một ứng dụng máy học – Machine Learning của hệ thống thị giác sử dụng Ignition IIoT Platform tại Frito-Lay, McClusky cho biết công ty đã áp dụng nó vào một khu vực của một đường nơi đặt một chiếc cân để cân khoai tây. Frito-Lay muốn sử dụng hệ thống quan sát để xác định mật độ của khoai tây trên dây chuyền để có thể điều chỉnh thời gian nấu cho phù hợp cho từng mẻ. Họ đã có thể làm điều này thành công, cho phép họ loại bỏ việc đổ một phần khoai tây để cân.
Bất kể bạn định sử dụng loại ứng dụng máy học nào hoặc bạn áp dụng thuật toán nào, bạn cần có dữ liệu tốt ngay từ đầu, có nghĩa là bạn cần có chiến lược tìm kiếm và xử lý dữ liệu phù hợp để đảm bảo chất lượng của nó. McClusky nói: “Sử dụng số liệu thống kê để lấy mẫu dữ liệu để biết nó có tốt không. “Bạn cần biết toàn bộ vũ trụ về những gì bạn đang giải quyết để có được kết quả tốt. Vì vậy, bạn không thể chỉ lấy dữ liệu lịch sử của riêng mình; bạn phải xem xét kỹ thuật lấy mẫu và mối tương quan so với nhân quả. Sau đó, hãy xem xét kết quả của bạn tốt như thế nào. Đây là nơi mà kiến thức miền và kiến thức về các quy trình là quan trọng. Các chuyên gia miền — không phải nhà khoa học dữ liệu — biết loại dữ liệu nào hứa hẹn và khi nào kết quả không có ý nghĩa ”.
Triển khai
Với sự hiểu biết tốt về các loại máy học và các thuật toán hỗ trợ chúng, bước tiếp theo là bắt đầu suy nghĩ về các ứng dụng. Applebaum đã vạch ra 5 bước sau để triển khai máy học – Machine Learning thành công: xác định (các) vấn đề bạn muốn giải quyết, thu thập dữ liệu, tạo mô hình, triển khai mô hình và giám sát để thành công.
Để xác định vấn đề, Applebaum cho biết tốt nhất nên chọn một câu hỏi bạn muốn trả lời. Ví dụ, bạn có muốn cải thiện một quy trình cụ thể, giảm thiểu các khiếm khuyết, v.v.? Khi làm điều này, hãy cẩn thận giữa quyết định có giá trị cao và quyết định dễ dàng, cô lưu ý. “Trước tiên hãy Triển khai dễ dàng, bởi vì [các dự án] có giá trị cao có thể là một nơi khó bắt đầu,” cô khuyên.
Với điều đó, Applebaum nhấn mạnh rằng điều quan trọng vẫn là, ngay cả với các dự án máy học dễ dàng, để đảm bảo có một số giá trị thu được chứ không phải để nó là một dự án tồn tại chỉ vì mục đích trình diễn công nghệ. “Hiểu hàm chi phí — sự khác biệt giữa dự đoán và kết quả thực tế dựa trên những gì bạn đang cố gắng Triển khai .”
Đây là một lĩnh vực khác mà kiến thức miền có thể đóng một vai trò lớn trong các ứng dụng máy học – Machine Learning về việc lựa chọn dữ liệu hữu ích cho dự án, thu thập dữ liệu còn thiếu, đảm bảo đầu vào dữ liệu chất lượng và xác định các biến phụ thuộc (tức là các điểm dữ liệu được liên kết với nhau, chẳng hạn như nhiệt độ và thời gian trong ngày).
McClusky nói thêm rằng, khi Triển khai một dự án máy học – Machine Learning , hãy đảm bảo sử dụng tải chuyển đổi trích xuất (ETL) để thu thập dữ liệu chứ không phải chính cơ sở dữ liệu sản xuất. Tự động hóa quá trình thu thập dữ liệu [với ETL] để dữ liệu được thu thập, làm sạch và các giá trị bị thiếu được xử lý tự động.
Sau đó, bắt đầu trực quan hóa dữ liệu trong Ignition IIoT Platform để giúp hiểu dữ liệu đó, vì vậy bạn có thể biết loại thuật toán nào bạn muốn áp dụng, Applebaum khuyên, thêm vào “Và đừng ngại thử nhiều hơn một [thuật toán].” Ignition IIoT Platform cung cấp phương tiện K, quét cơ sở dữ liệu, mạng nơ-ron và các phép hồi quy đơn giản. Amazon Web Services, Microsoft Azure và Google Cloud cung cấp các công cụ khác để phân tích thêm.
Applebaum lưu ý: “Rất nhiều người cố gắng bỏ qua quá trình thử nghiệm này. “Nhưng đừng làm vậy. Đảm bảo rằng các mô hình của bạn thực sự dự đoán những điều bạn chưa thấy trước đây. Quay lại và kiểm tra lại nếu cần để có được một mô hình hữu ích. Tốt hơn là bạn nên dành thời gian ở đây để giải quyết vấn đề còn hơn là phải khắc phục sự cố sau này ”.




















