










Chất lượng dữ liệu kém là kẻ thù số một đối với việc sử dụng dữ liệu rộng rãi, gây bất lợi cho việc ứng dụng machine learning . Trong khi quan sát các dữ liệu trong những dự án Machine Learning đã khiến các nhà phân tích lo lắng khi đưa ra quyết định cho các vấn đề sản xuất và kinh doanh, đây là một cảnh báo đặc biệt cho việc ứng dụng machine learning . Nhu cầu chất lượng của machine learning là rất lớn và dữ liệu xấu có thể tạo nên sự thất bại của nó 2 lần- lần đầu tiên trong dữ liệu lịch sử được sử dụng để huấn luyện mô hình dự đoán và và đầu thứ hai trong dữ liệu mới được sinh ra bởi mô hình đó để đưa ra quyết định trong tương lai.
Để đào tạo đúng một mô hình dự đoán, dữ liệu lịch sử phải đáp ứng các tiêu chuẩn chất lượng cao và đặc biệt là rộng. Đầu tiên, dữ liệu phải đúng: Nó phải chính xác, được dán nhãn chính xác, không được mất các dữ liệu quan trọng, v.v. Nhưng bạn cũng phải có dữ liệu phù hợp – rất nhiều dữ liệu không thiên vị chủ quan , trên toàn bộ phạm vi đầu vào mà một mục tiêu nhằm phát triển mô hình dự đoán. Hầu hết các công việc chất lượng dữ liệu tập trung vào tiêu chí này hay tiêu chí khác, nhưng đối với machine learning , bạn phải làm việc trên cả hai đầu việc này cùng một lúc.
Tuy nhiên, ngày nay, hầu hết các dữ liệu không đáp ứng được dữ liệu cơ bản là đúng tiêu chuẩn . Lý do bao gồm từ những người tạo dữ liệu không hiểu những gì được mong đợi từ nó, đến thiết bị đo lường được hiệu chuẩn kém, đến các quy trình quá phức tạp, và cuối cùng là lỗi của con người. Để bù đắp, các nhà khoa học dữ liệu cần làm sạch dữ liệu trước khi đào tạo mô hình dự đoán. Đây là công việc tốn thời gian và tẻ nhạt (chiếm tới 80% thời gian của các nhà khoa học dữ liệu ) và đó là vấn đề mà các nhà khoa học phàn nàn về hầu hết . Ngay cả với những nỗ lực như vậy, việc làm sạch không phát hiện cũng không sửa chữa tất cả các lỗi và cho đến nay, không có cách nào để hiểu tác động lên mô hình dự đoán. Hơn nữa, dữ liệu không phải lúc nào cũng đáp ứng các tiêu chuẩn dữ liệu phù hợp với các tiêu chuẩn, như các báo cáo về sự thiên vị chủ quan trong nhận dạng khuôn mặt và chứng thực.
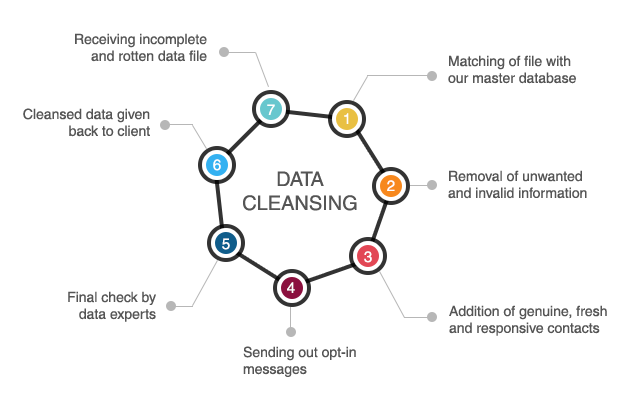
Các vấn đề ngày càng phức tạp đòi hỏi không chỉ nhiều dữ liệu, mà còn đa dạng hơn, dữ liệu toàn diện. Và với điều này đi kèm nhiều vấn đề chất lượng. Ví dụ, các ghi chú viết tay và các từ viết tắt có những nỗ lực hỗ trơ phức tạp của IBM trong việc áp dụng machine learning (ví dụ: Watson) vào điều trị ung thư.
Chất lượng dữ liệu không kém phần rắc rối khi triển khai . Hãy xem xét một tổ chức tìm kiếm tăng năng suất với chương trình machine learning . Trong khi nhóm khoa học dữ liệu phát triển mô hình dự đoán có thể đã triển khai một công việc vững chắc là làm sạch dữ liệu để đào tạo, nó vẫn có thể bị tổn hại bởi dữ liệu xấu trong tương lai. Một lần nữa, phải mất rất nhiều trong số họ – để tìm và sửa lỗi. Điều này đến lượt nó thay đổi mức tăng năng suất hy vọng. Hơn nữa, khi các công nghệ machine learning thâm nhập vào các tổ chức, đầu ra của một mô hình dự đoán sẽ cung cấp cho mô hình tiếp theo, và tiếp theo, v.v., thậm chí vượt qua ranh giới công ty.
Bạn có thể thích



Rủi ro là một lỗi nhỏ ở một bước sẽ xếp tầng, gây ra nhiều lỗi hơn và ngày càng lớn hơn trong toàn bộ quá trình.
Những mối quan tâm này phải được đáp ứng với một chương trình chất lượng tích cực, được triển khai tốt, tham gia nhiều hơn so với yêu cầu cho kinh doanh hàng ngày, hàng ngày. Nó đòi hỏi các nhà lãnh đạo của nỗ lực tổng thể để triển khai tất cả năm bước sau đây.
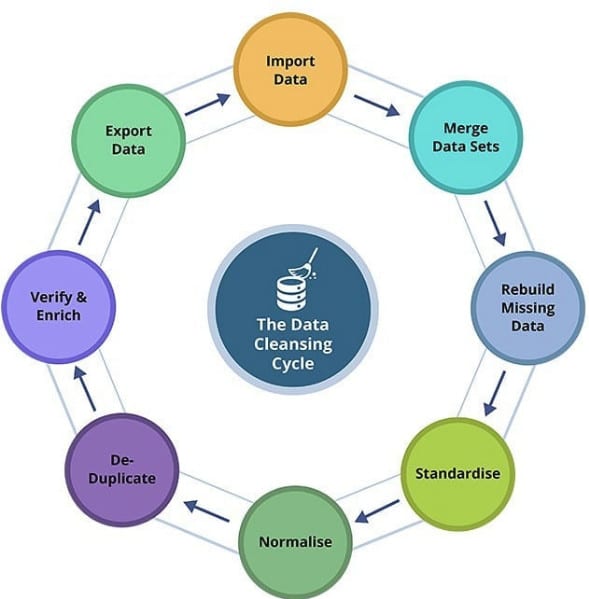
Đầu tiên, bạn cần làm rõ các mục tiêu của bạn và đánh giá xem bạn có dữ liệu phù hợp để hỗ trợ các mục tiêu này hay không. Chúng ta hãy xem xét một công ty thế chấp muốn áp dụng machine learning vào quy trình cho vay. Có nên cấp khoản vay và, nếu vậy, theo điều khoản nào? Các mục tiêu có thể sử dụng machine learning bao gồm:
- Giảm chi phí của quá trình quyết định hiện tại. Vì việc đưa ra quyết định tốt hơn không phải là một mục tiêu, dữ liệu hiện tại có thể là đầy đủ.
- Loại bỏ sự thiên vị chủ quan từ quá trình quyết định hiện có. Sự thiên vị chủ quan này gần như chắc chắn được phản ánh trong dữ liệu hiện có của nó và Tiến hành thận trọng.
- Cải thiện quy trình ra quyết định – cấp ít khoản vay hơn mặc định và phê duyệt các khoản vay bị từ chối trước đó sẽ triển khai . Lưu ý rằng mặc dù công ty có nhiều dữ liệu về các khoản thế chấp bị từ chối trước đó, nhưng không biết liệu các khoản thế chấp này có được triển khai hay không và Tiến hành hết sức thận trọng.
Khi dữ liệu không đạt được mục tiêu, cách tốt nhất là tìm dữ liệu mới, thu nhỏ lại các mục tiêu hoặc cả hai.
Thứ hai là xây dựng nhiều thời gian để triển khai các nguyên tắc cơ bản về chất lượng dữ liệu vào kế hoạch dự án tổng thể của bạn. Đối với đào tạo, điều này có nghĩa là sẽ có bốn tháng làm sạch cho mỗi người mỗi tháng xây dựng mô hình, vì bạn phải đo lường mức chất lượng, đánh giá nguồn dữ liệu , khử trùng lặp và dữ liệu đào tạo sạch, giống như bất kỳ phân tích quan trọng nào . Đối với việc triển khai, tốt nhất là loại bỏ các nguyên nhân gốc của lỗi và do đó giảm thiểu việc làm sạch liên tục. Làm như vậy sẽ có tác dụng mạnh mẽ trong việc loại bỏ các nhà máy dữ liệu ẩn, giúp bạn tiết kiệm thời gian và tiền bạc trong hoạt động. Bắt đầu công việc này càng sớm càng tốt và ít nhất sáu tháng trước khi bạn muốn thả lỏng mô hình dự đoán tự động của mình.
Thứ ba, duy trì một lộ trình kiểm toán khi bạn chuẩn bị dữ liệu đào tạo. Duy trì một bản sao dữ liệu đào tạo ban đầu của bạn, dữ liệu bạn đã sử dụng trong đào tạo và các bước được sử dụng để có được từ lần đầu tiên đến lần thứ hai. Làm như vậy chỉ đơn giản là best practice (mặc dù nhiều người bỏ qua nó một cách không chính xác) và nó có thể giúp bạn triển khai các cải tiến quy trình mà bạn sẽ cần sử dụng mô hình dự đoán của mình trong các quyết định trong tương lai. Hơn nữa, điều quan trọng là phải hiểu những thành kiến và giới hạn trong mô hình của bạn và quy trình kiểm toán có thể giúp bạn sắp xếp nó.
Thứ tư, tính phí một cá nhân (hoặc nhóm) cụ thể chịu trách nhiệm về chất lượng dữ liệu khi bạn biến mô hình của mình trở nên lỏng lẻo. Người này nên có kiến thức sâu sắc về dữ liệu, bao gồm cả điểm mạnh và điểm yếu của nó, và có hai trọng tâm. Đầu tiên, ngày này qua ngày khác, họ đặt ra và thực thi các tiêu chuẩn về chất lượng dữ liệu đến. Nếu dữ liệu không đủ tốt, con người phải tiếp quản. Thứ hai, họ dẫn đầu các nỗ lực liên tục để tìm và loại bỏ nguyên nhân gốc của lỗi. Công việc này đã bắt đầu và nó phải tiếp tục theo thời gian.
Cuối cùng cần có được độc lập, đảm bảo chất lượng nghiêm ngặt. Như được sử dụng ở đây, đảm bảo chất lượng là quá trình đảm bảo rằng chương trình chất lượng cung cấp kết quả mong muốn. Khẩu hiệu ở đây là độc lập, vì vậy công việc này nên được triển khai bởi những người khác – một bộ phận QA nội bộ, một nhóm từ bên ngoài bộ phận hoặc một bên thứ ba đủ điều kiện.
Ngay cả sau khi triển khai năm bước này, bạn chắc chắn sẽ thấy rằng dữ liệu của mình không hoàn hảo. Bạn có thể điều chỉnh một số vấn đề về chất lượng dữ liệu nhỏ trong mô hình dự đoán, chẳng hạn như một giá trị bị thiếu duy nhất trong số mười lăm biến quan trọng nhất. Để khám phá khu vực này, hãy ghép các nhà khoa học dữ liệu và doanh nhân giàu kinh nghiệm nhất của bạn khi chuẩn bị dữ liệu và đào tạo mô hình.
Tác giả : Thomas C. Redman, “the Data Doc,” is President of Data Quality Solutions.




















