












Không có cuộc thảo luận nào về Dữ liệu lớn nào mà không đưa tên Hadoop và MongoDB , hai trong số các software database nổi bật nhất hiện có. Vì có rất nhiều thông tin có sẵn trên cả hai database này, đặc biệt là những ưu điểm và nhược điểm tương ứng của chúng, việc chọn đúng database đặt ra một thách thức cho nhà phát triển.
Vì cả hai nền tảng đều có công dụng của chúng, cái nào hữu ích nhất cho bạn và tổ chức của bạn? Bài viết này là một hướng dẫn để giúp bạn đưa ra lựa chọn quan trọng giữa hai ứng cử viên này.
Hadoop là gì?
Hadoop là một bộ chương trình mã nguồn mở mà bạn có thể sử dụng và sửa đổi cho các quy trình dữ liệu lớn của mình. Hadoop được tạo thành từ 4 mô-đun, mỗi mô-đun thực hiện một nhiệm vụ cụ thể liên quan đến phân tích dữ liệu lớn.
Những nền tảng này bao gồm:
- Hệ thống tệp phân tán
- MapReduce
- Hadoop Common
- Hadoop YARN
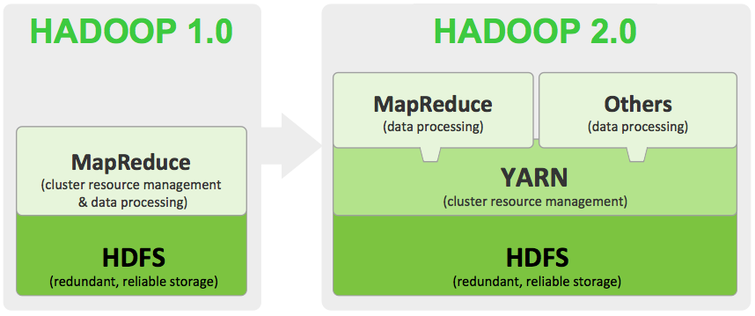
Hệ thống tệp phân tán (HDFS)
Đây là một trong hai thành phần quan trọng nhất của Hadoop. Một hệ thống tệp phân tán (viết tắt là DFS) rất quan trọng vì:
- HDFS cho phép dữ liệu dễ dàng được lưu trữ, chia sẻ và truy cập trên một mạng lưới rộng lớn các máy chủ được liên kết.
- HDFS làm cho nó có thể làm việc với dữ liệu như thể bạn đang làm việc từ bộ nhớ cục bộ.
- Không giống như các tùy chọn lưu trữ, chẳng hạn như hệ thống tệp chia sẻ đĩa giới hạn quyền truy cập dữ liệu cho người dùng Offline , bạn có thể truy cập dữ liệu ngay cả khi Offline .
- DFS của Hadoop không giới hạn ở hệ điều hành của máy chủ; bạn có thể truy cập nó bằng bất kỳ máy tính hoặc hệ điều hành được hỗ trợ nào.
MapReduce
MapReduce là phần thứ hai trong hai mô-đun quan trọng nhất và đó là thứ cho phép bạn làm việc với dữ liệu trong Hadoop. Nó thực hiện hai nhiệm vụ:
- Map – Ánh xạ – bao gồm chuyển đổi một tập hợp dữ liệu thành định dạng có thể dễ dàng phân tích. Nó thực hiện điều này bằng cách lọc và sắp xếp.
- Reduce – theo sau ánh xạ. Reduce thực hiện các hoạt động toán học (ví dụ: đếm số lượng khách hàng trên 21 tuổi) trên sản lượng công việc mapping.
Hadoop Common
Hadoop Common là một tập hợp các công cụ (thư viện và tiện ích) hỗ trợ ba mô-đun Hadoop khác. Nó cũng chứa các tập lệnh và mô-đun cần thiết để khởi động Hadoop, cũng như mã nguồn, tài liệu và phần đóng góp của cộng đồng Hadoop.
Hadoop YARN
Đó là khung kiến trúc cho phép quản lý tài nguyên và lập kế hoạch công việc. Đối với các nhà phát triển Hadoop, YARN cung cấp một cách hiệu quả để viết các ứng dụng và thao tác với các bộ dữ liệu lớn. Hadoop YARN có thể xử lý đồng thời : interactive, streaming, and batch processing.
Tại sao chúng ta nên sử dụng Hadoop?
Chúng ta đã biết Hadoop là gì , điều tiếp theo cần được khám phá là TẠI SAO phải sử dụng Hadoop. Ở đây để bạn xem xét là sáu lý do tại sao Hadoop có thể phù hợp nhất cho công ty của bạn và nhu cầu của nó để tận dụng dữ liệu lớn.

- Bạn có thể nhanh chóng lưu trữ và xử lý một lượng lớn dữ liệu khác nhau. Có một khối lượng dữ liệu ngày càng tăng được tạo ra từ IoT và phương tiện truyền thông xã hội. Điều này làm cho khả năng của Hadoop trở thành tài nguyên chính để xử lý các nguồn dữ liệu khối lượng lớn này.
- Hệ thống tệp phân tán cung cấp cho Hadoop khả năng tính toán cao cần thiết cho việc tính toán dữ liệu nhanh.
- Hadoop bảo vệ chống lỗi phần cứng bằng cách chuyển hướng công việc sang các nút khác và tự động lưu trữ nhiều bản sao dữ liệu.
- Bạn có thể lưu trữ nhiều loại dữ liệu có cấu trúc hoặc không cấu trúc (bao gồm cả hình ảnh và video) mà không cần phải xử lý trước.
- Khung nguồn mở chạy trên các máy chủ, có hiệu quả chi phí hơn so với lưu trữ chuyên dụng.
- Thêm các nút cho phép một hệ thống mở rộng quy mô để xử lý các tập dữ liệu ngày càng tăng. Điều này được thực hiện với ít quản trị.
Xem thêm : Giới thiệu một số công cụ phân tích dữ liệu lớn Big Data Analytics
Hạn chế của Hadoop
Cũng như Hadoop, tuy nhiên nó vẫn có những hạn chế riêng. Trong số những nhược điểm này:
- Do tính lập trình của nó, MapReduce phù hợp cho các yêu cầu đơn giản. Bạn có thể làm việc với các đơn vị độc lập, nhưng không hiệu quả bằng các tác vụ tương tác và lặp lại. Không giống như các tác vụ độc lập cần sắp xếp và xáo trộn đơn giản, các tác vụ lặp lại yêu cầu nhiều bản đồ và giảm các quy trình để hoàn thành. Kết quả là, nhiều tệp được tạo giữa bản đồ và giảm các pha, làm cho nó không hiệu quả ở các phân tích nâng cao.
- Chỉ có một vài lập trình viên cấp mới có các kỹ năng java cần thiết để làm việc với MapReduce. Điều này đã chứng kiến các nhà cung cấp đổ xô đưa SQL lên hàng đầu của Hadoop vì các lập trình viên có kỹ năng về SQL dễ tìm thấy hơn.
- Hadoop là một ứng dụng phức tạp và đòi hỏi một mức độ kiến thức phức tạp để kích hoạt các chức năng như giao thức bảo mật. Ngoài ra, Hadoop thiếu lưu trữ và mã hóa mạng.
- Hadoop không cung cấp một bộ công cụ đầy đủ cần thiết để xử lý siêu dữ liệu hoặc để quản lý, làm sạch và đảm bảo chất lượng dữ liệu.
- Thiết kế phức tạp của nó làm cho nó không phù hợp để xử lý lượng dữ liệu nhỏ hơn vì nó không thể hỗ trợ đọc ngẫu nhiên các tệp nhỏ một cách hiệu quả.
- Nhờ thực tế là khung của Hadoop được viết gần như hoàn toàn bằng Java, một ngôn ngữ lập trình ngày càng bị xâm phạm bởi tội phạm mạng, nền tảng này đặt ra những rủi ro bảo mật đáng chú ý
MongoDB là gì?
MongoDB là một nền tảng quản lý cơ sở dữ liệu NoQuery rất linh hoạt và có khả năng mở rộng, dựa trên tài liệu, có thể chứa các mô hình dữ liệu khác nhau và lưu trữ dữ liệu trong các bộ giá trị khóa. Nó được phát triển như một giải pháp để làm việc với khối lượng lớn dữ liệu phân tán không thể xử lý hiệu quả trong các mô hình quan hệ, thường chứa các hàng và bảng. Giống như Hadoop, MongoDB là nguồn mở và miễn phí.

Một số tính năng chính của MongoDB bao gồm:
- Đây là ngôn ngữ truy vấn phong phú và hỗ trợ tìm kiếm văn bản, tính năng tổng hợp và hoạt động CRUD.
- Nó đòi hỏi các hoạt động đầu vào và đầu ra ít hơn do các mô hình dữ liệu nhúng, không giống như các cơ sở dữ liệu quan hệ. Các chỉ mục MongoDB cũng hỗ trợ các truy vấn nhanh hơn.
- MongoDB cung cấp khả năng chịu lỗi bằng cách tạo bộ dữ liệu bản sao. Sao chép đảm bảo dữ liệu được lưu trữ trên nhiều máy chủ, tạo dự phòng và đảm bảo tính sẵn sàng cao.
- MongoDB có tính năng sharding, làm cho khả năng mở rộng theo chiều ngang có thể. Điều này hỗ trợ tăng nhu cầu dữ liệu với chi phí thấp hơn so với các phương pháp xử lý tăng trưởng hệ thống theo chiều dọc.
- MongoDB sử dụng nhiều công cụ lưu trữ, do đó đảm bảo sử dụng đúng công cụ cho khối lượng công việc phù hợp, từ đó nâng cao hiệu suất.
Các công cụ lưu trữ bao gồm:
-
WiredTiger
Đây là công cụ mặc định được sử dụng trong các triển khai mới cho các phiên bản 3.2 trở lên. Nó có thể xử lý hầu hết khối lượng công việc. Các tính năng của nó bao gồm kiểm tra điểm, nén và đồng thời ở cấp độ tài liệu cho các hoạt động ghi. Tính năng thứ hai cho phép nhiều người dùng sử dụng và chỉnh sửa tài liệu đồng thời.
-
Công cụ lưu trữ trong bộ nhớ (In-Memory Storage Engine)
Công cụ này lưu trữ tài liệu trong bộ nhớ thay vì trên đĩa. Điều này làm tăng khả năng dự đoán của độ trễ dữ liệu.
-
Công cụ lưu trữ MMAPv1 (MMAPv1 Storage Engine)
Đây là bộ lưu trữ sớm nhất cho MongoDB và chỉ hoạt động trên V3.0 trở về trước. Nó hoạt động tốt cho khối lượng công việc liên quan đến cập nhật, đọc và chèn số lượng lớn on-premise.
Tại sao chúng ta nên sử dụng MongoDB?
Các doanh nghiệp ngày nay yêu cầu truy cập nhanh chóng và linh hoạt vào dữ liệu của họ để có được những hiểu biết có ý nghĩa và đưa ra quyết định tốt hơn. Các tính năng của MongoDB phù hợp hơn để giúp đáp ứng những thách thức dữ liệu mới này. Trường hợp của MongoDB vì đã được sử dụng theo các lý do sau:
- Khi sử dụng cơ sở dữ liệu quan hệ, bạn cần một vài bảng để xây dựng. Với mô hình dựa trên tài liệu của Mongo, bạn có thể biểu diễn một cấu trúc trong một thực thể duy nhất, đặc biệt là đối với dữ liệu không thay đổi.
- Ngôn ngữ truy vấn được MongoDB sử dụng có hỗ trợ truy vấn động.
- Lược đồ trong MongoDB là ẩn, có nghĩa là bạn không phải thực thi nó. Điều này làm cho việc biểu diễn kế thừa trong cơ sở dữ liệu dễ dàng hơn ngoài việc cải thiện lưu trữ dữ liệu đa hình.
- Lưu trữ chiều ngang giúp dễ dàng mở rộng quy mô.
Hạn chế của MongoDB
Mặc dù MongoDB kết hợp các tính năng tuyệt vời để đối phó với nhiều thách thức trong dữ liệu lớn, nhưng nó đi kèm với một số hạn chế, chẳng hạn như:
- Để sử dụng các phép nối, bạn phải thêm mã thủ công, điều này có thể khiến việc thực thi chậm hơn và hiệu suất thấp hơn mức tối ưu.
- MongoDB yêu cầu rất nhiều bộ nhớ vì tất cả các tệp phải được ánh xạ từ đĩa vào bộ nhớ.
- Kích thước tài liệu không thể lớn hơn 16MB.
- Chức năng lồng nhau bị giới hạn và không thể vượt quá 100 cấp độ.
Chúng ta nên sử dụng gì cho dữ liệu lớn? MongoDB hay Hadoop?
Để trả lời câu hỏi này, bạn có thể xem và xem những công ty lớn nào sử dụng nền tảng nào và cố gắng làm theo practice của họ. Ví dụ: eBay, SAP, Adobe, LinkedIn, McAfee, MetLife và Foursquare sử dụng MongoDB. Mặt khác, Microsoft, Cloudera, IBM, Intel, Teradata, Amazon, Map R Technologies được tính trong số những người dùng Hadoop đáng chú ý.

Cuối cùng, cả Hadoop và MongoDB đều là những lựa chọn phổ biến để xử lý dữ liệu lớn. Tuy nhiên, mặc dù chúng có nhiều điểm tương đồng (ví dụ, mã nguồn mở, NoQuery, không có lược đồ và MapReduce ), cách tiếp cận của chúng để xử lý và lưu trữ dữ liệu là khác nhau. Đó chính xác là sự khác biệt cuối cùng giúp chúng ta xác định lựa chọn tốt nhất giữa Hadoop so với MongoDB .
Bạn có thể thích




Không có ứng dụng phần mềm duy nhất có thể giải quyết tất cả các vấn đề của bạn. Các Định lý CAP sẽ giúp hình dung tắc nghẽn trong các ứng dụng bằng cách chỉ ra rằng phân phối máy tính chỉ có thể thực hiện một cách tối ưu về hai trong số ba mặt trận, những xử lý hạnh phúc, sự khoan dung phân vùng, và tính sẵn sàng. Khi chọn ứng dụng dữ liệu lớn để sử dụng, bạn phải chọn hệ thống có hai thuộc tính phổ biến nhất mà bạn cần.
Hệ thống quản lý cơ sở dữ liệu quan hệ thì sao?
Cả Hadoop và MongoDB đều cung cấp nhiều lợi thế hơn so với các hệ thống quản lý cơ sở dữ liệu quan hệ truyền thống (RDBMS), bao gồm xử lý song song, khả năng mở rộng, khả năng xử lý dữ liệu tổng hợp với khối lượng lớn, kiến trúc MapReduce và hiệu quả chi phí do là nguồn mở. Hơn nữa, họ xử lý dữ liệu trên các nút hoặc cụm, tiết kiệm chi phí phần cứng. Tuy nhiên, trong bối cảnh so sánh chúng với RDBMS, mỗi nền tảng có một số điểm mạnh so với nền tảng khác.
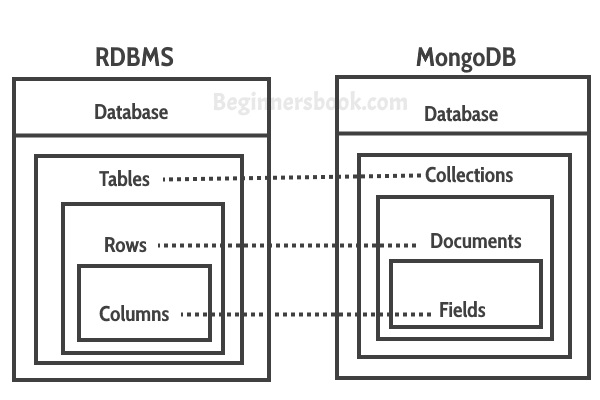
Thay thế RDBMS
MongoDB là một nền tảng linh hoạt có thể tạo ra một sự thay thế phù hợp cho RDBMS. Hadoop không thể thay thế RDBMS mà thay vào đó bổ sung nó bằng cách giúp lưu trữ dữ liệu.
Xử lý bộ nhớ
MongoDB là một cơ sở dữ liệu dựa trên C ++, giúp xử lý bộ nhớ tốt hơn. Hadoop là một bộ phần mềm dựa trên Java cung cấp khung để lưu trữ, truy xuất và xử lý. Hadoop tối ưu hóa không gian tốt hơn MongoDB.
Nhập và lưu trữ dữ liệu
Dữ liệu trong MongoDB được lưu trữ dưới dạng JSON, BSON hoặc nhị phân và tất cả các trường có thể được truy vấn, lập chỉ mục, tổng hợp hoặc sao chép cùng một lúc. Ngoài ra, dữ liệu trong MongoDB phải được nhập ở định dạng JSON hoặc CSV để được nhập. Hadoop chấp nhận các định dạng dữ liệu khác nhau, do đó loại bỏ nhu cầu chuyển đổi dữ liệu trong quá trình xử lý.
Xử lý dữ liệu lớn
MongoDB không được xây dựng với dữ liệu lớn trong tâm trí. Mặt khác, Hadoop được xây dựng cho mục đích duy nhất đó. Như vậy, thứ hai là tuyệt vời trong xử lý hàng loạt và chạy các công việc ETL dài. Ngoài ra, các tệp nhật ký được Hadoop xử lý tốt nhất do kích thước lớn và xu hướng tích lũy nhanh chóng. Việc triển khai MapReduce trên Hadoop hiệu quả hơn so với MongoDB, một lần nữa làm cho nó trở thành một lựa chọn tốt hơn để phân tích các tập dữ liệu lớn.
Xử lý dữ liệu thời gian thực
MongoDB xử lý phân tích dữ liệu thời gian thực tốt hơn và cũng là một lựa chọn tốt để phân phối dữ liệu phía máy khách do dữ liệu có sẵn của nó. Ngoài ra, lập chỉ mục không gian địa lý của MongoDB làm cho nó lý tưởng cho việc thu thập và phân tích không gian địa lý hoặc dữ liệu địa lý trong thời gian thực. Mặt khác, Hadoop không giỏi xử lý dữ liệu thời gian thực, nhưng nếu bạn chạy các truy vấn giống như Hadoop SQL trên Hive, bạn có thể thực hiện các truy vấn dữ liệu với tốc độ nhanh hơn và hiệu quả hơn JSON.
theo http://simplilearn.com/



























