














Dự đoán thời gian sử dụng hữu ích còn lại (RUL) là một trong những lợi ích cốt lõi của cách tiếp cận Công nghiệp 4.0. Do việc triển khai nhanh chóng các thiết bị Internet of Things (IoT), các nguồn dữ liệu cho các biến như độ rung, áp suất, dòng điện và nhiệt độ hiện đang trở nên phổ biến và sẵn có. Điều này — cùng với hồ sơ bảo trì kỹ thuật số — cung cấp thông tin chi tiết về tình trạng thiết bị hơn bao giờ hết.
Quyền truy cập vào dữ liệu này không thể đến vào thời điểm thích hợp hơn. Đồng thời với sự bùng nổ của thiết bị kỹ thuật số mới là hai bước phát triển quan trọng khác: lực lượng lao động lão hóa và tiến bộ học sâu. Trước đây, việc dự đoán thời điểm nên thay thế thiết bị chủ yếu dựa vào thông tin đầu vào của chuyên gia về vấn đề đó. Chuyên môn này phụ thuộc vào những cá nhân được chọn có kiến thức chuyên môn cao. Khi lực lượng lao động ở Hoa Kỳ tiếp tục già đi, nhiều cá nhân trong số này đang rời bỏ ngành và tạo ra lỗ hổng kiến thức đáng kể. Ngoài ra, sự ra đời của GPU giá rẻ và các mô hình sâu hơn đáng kể đã làm tăng tiềm năng cho các tùy chọn trí tuệ nhân tạo chất lượng cao để dự đoán lỗi trước khi nó xảy ra. Trước khi chúng ta chuyển sang phương pháp luận, chúng ta hãy xem Cuộc sống hữu ích còn lại (RUL) là gì.
Cuộc sống hữu ích còn lại (RUL) là gì?
RUL là khoảng thời gian máy có khả năng hoạt động trước khi cần sửa chữa hoặc thay thế. Bằng cách tính đến RUL, các kỹ sư có thể lên lịch bảo trì, tối ưu hóa hiệu quả vận hành và tránh thời gian ngừng hoạt động ngoài dự kiến. Mặc dù có nhiều sắc thái nhưng khái niệm này khác khi so sánh với phát hiện bất thường. Tính năng phát hiện bất thường có thể góp phần dự đoán thời gian sử dụng hữu ích còn lại, nhưng tính năng này tập trung nhiều hơn vào các sự kiện mới nổi sẽ làm giảm hiệu suất thiết bị một cách nhanh chóng. RUL tập trung nhiều hơn vào quản lý tài sản dài hạn và được đo lường theo năm chứ không phải theo ngày.
Phương pháp RUL dự đoán
Các phương pháp được sử dụng để dự đoán RUL rất đa dạng, nhưng có thể được chia thành ba loại cơ bản:
- Hệ thống dựa trên chuyên gia: Kiểu tiếp cận này tương đối đơn giản và chủ yếu dựa vào đầu vào của con người. Về cơ bản, hệ thống này chỉ so sánh dữ liệu hiện tại với các trường hợp được phân loại bởi chuyên gia đã quan sát trước đó. Đây là các quy tắc hoặc ngưỡng do con người phát triển được gắn với một RUL cụ thể. Các quy tắc này có thể đơn giản được chứa trong một thủ tục/sách hướng dẫn hoặc gắn với một đầu ra logic mờ. Trong tất cả các phương pháp, đây là phương pháp ít chính xác nhất, vì đầu ra về cơ bản sẽ rời rạc. Ngoài ra, nó có thể không xử lý tốt các sự kiện chưa được phân tích trước đó. Nó cũng đòi hỏi rất nhiều thông tin đầu vào ban đầu từ một chuyên gia về chủ đề.
- Hệ thống dựa trên vật lý: Các hệ thống dựa trên vật lý về cơ bản là các mô hình toán học làm bằng tay, được thiết kế để dự đoán sự xuống cấp trong tương lai dựa trên các đặc điểm vật lý. Lưu ý rằng các mô hình này là chế độ lỗi cụ thể. Ví dụ, vào năm 1962, một phương pháp đã được đề xuất cho sự phát triển của các vết nứt dựa trên vật liệu và các biến thể dưới tác dụng của tải trọng. Những loại mô hình này có thể có độ chính xác cao nhưng đòi hỏi kiến thức chuyên môn và thông tin đầu vào quan trọng.
- Học máy-Dựa trên mô hình: Trong tất cả các phương pháp được cung cấp ở đây, phương pháp này là phương pháp dễ tổng quát nhất và yêu cầu rất ít thông tin đầu vào của chuyên gia thiết bị. Nó dựa trên thống kê, nghĩa là cần một lượng lớn dữ liệu chất lượng cao để phát triển mô hình ban đầu. Phương pháp này được giải thích thêm trong phần tiếp theo.
Phương pháp dựa trên Machine Learning
#1: Được giám sát
Phương pháp học máy có giám sát có thể là phương pháp trực quan nhất, nhưng nó có xu hướng tốn kém nhất từ góc độ chú thích dữ liệu. Để thực sự có thể đào tạo một mô hình được giám sát hoàn toàn, người ta cần một lượng dữ liệu khổng lồ với nhiều lần chạy trong toàn bộ vòng đời để có hiệu quả. Ngoài ra, mặc dù phát hiện bất thường và RUL là hai thứ khác nhau, nhưng khả năng cung cấp đầu vào phát hiện bất thường vào mô hình RUL là rất quan trọng. Theo định nghĩa của phát hiện bất thường, dữ liệu chỉ đơn giản là bất thường. Điều này có nghĩa là ngay cả với bộ đệm dữ liệu lớn, một số tình huống nhất định có thể không xuất hiện. Để giúp hình dung khái niệm này, hãy xem hình 1 bên dưới.
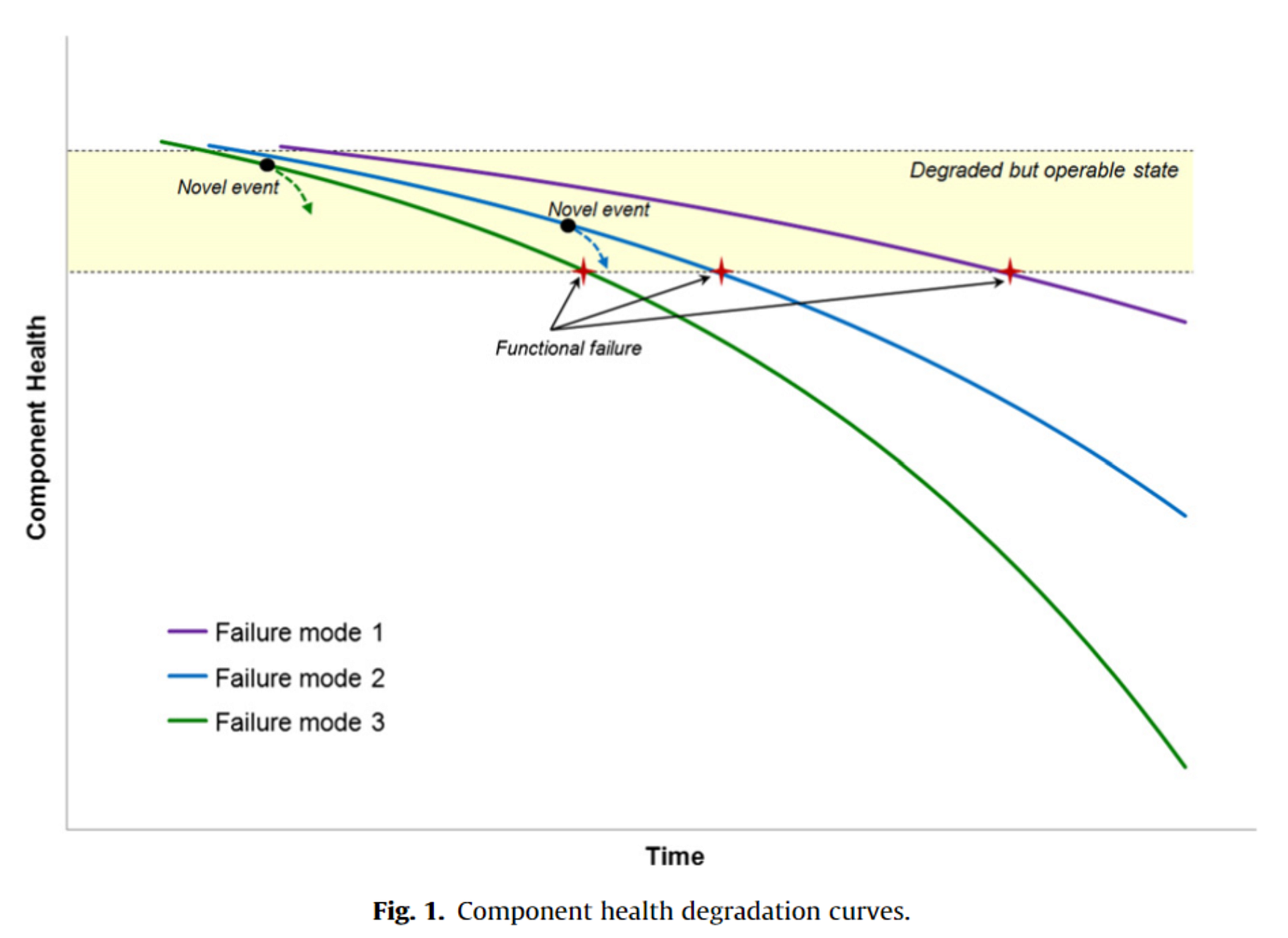
Mặc dù một số trường hợp nhất định chỉ liên quan đến tuổi tác, nhưng các đường cong xuống cấp khác gắn chặt hơn với một sự kiện trong vòng đời của tài sản. Ví dụ, một sự kiện quá điện áp trong tuổi thọ của một động cơ lớn có thể thay đổi đáng kể đường cong suy giảm của thành phần. Mô hình cần có khả năng xác định các hiện tượng này và cập nhật đường cong cho phù hợp. Có các phương pháp để sửa lỗi thiếu dữ liệu. Nhiều bộ dữ liệu tổng hợp tồn tại có thể được sử dụng để tăng cường dữ liệu trong thế giới thực. Một mô hình được giám sát có thể được đào tạo dựa trên mô phỏng của một máy bơm/động cơ lớn và sau đó được tinh chỉnh dựa trên dữ liệu trong thế giới thực cho các nội dung cụ thể được đề cập. Cuối cùng, đây là một vấn đề về chuỗi thời gian; một khối thời gian nhất định từ các cảm biến khác nhau có thể được cung cấp cho mô hình với biến dự đoán mục tiêu là tuổi thọ còn lại.
#2: Không giám sát
Mặc dù được điều tra ít hơn, nhưng các phương pháp tiếp cận RUL hoàn toàn không được giám sát vẫn tồn tại. Lợi ích của phương pháp này là không cần dán nhãn. Nói cách khác, dữ liệu được cung cấp trực tiếp cho mô hình và nó đưa ra các dự đoán. Một ví dụ như vậy về điều này sử dụng phương pháp Autoencoder. Loại mô hình này về cơ bản đưa ra cách dữ liệu “bình thường” dựa trên dữ liệu đã thấy trước đó. Điều này được kết hợp để tạo ra một số liệu có tên là Chỉ số sức khỏe ảo, sau đó được sử dụng làm đầu vào cho mô hình loại trí nhớ ngắn hạn dài hạn để đưa ra dự đoán RUL. Như người ta có thể nói từ ngày xuất bản, loại phương pháp luận này là một lợi thế. Nếu một người có thể sử dụng các phương pháp không giám sát để dự đoán chính xác RUL, thì đây sẽ là sự thay đổi mô hình cho lĩnh vực này.
#3: Bán giám sát
Phương pháp này đại diện cho một cái gì đó của sự thỏa hiệp giữa hai tùy chọn trên. Nó cho phép diễn ra quá trình đào tạo trước và xác định các loại giai đoạn xuống cấp trước bất kỳ quá trình học có giám sát nào. Bằng cách sử dụng bộ dữ liệu C-MAPPS (điểm chuẩn tiêu chuẩn trong lĩnh vực này), một phương pháp có thể tạo ra kết quả hiện đại nhất. Phương pháp này hơi phức tạp vì nó sử dụng máy Boltzman bị hạn chế song song với mô hình bộ nhớ ngắn hạn dài hạn, trong khi tất cả các tham số đều được tối ưu hóa thông qua việc sử dụng thuật toán di truyền. Trong ngắn hạn, cách tiếp cận bán giám sát này có thể sẽ là loại mô hình có trường hợp kinh doanh tốt nhất.
Nhận diện Công nghiệp 4.0
Để nhận ra đầy đủ lợi ích của Công nghiệp 4.0, các mô hình dự đoán RUL phải được phát triển và triển khai. Sự nhanh chóng triển khai cảm biến IoT cùng với sự mất mát ngày càng tăng của các chuyên gia chủ đề quan trọng bắt buộc sự phát triển này. Sự bùng nổ của dữ liệu có sẵn cho phép đạt được độ chính xác mà trước đây không thể đạt được. Với việc triển khai đúng cách, các lợi ích của Công nghiệp 4.0 có thể mang lại thời gian chạy tài sản lâu hơn và các chiến lược bảo trì tốt hơn đáng kể cho bất kỳ công ty nào.
Nguồn : https://www.iotforall.com/ .
Post by Automation Bot.






























