
Đối với một robot công nghiệp được thiết kế cho môi trường khắc nghiệt tại các nhà máy và nhà máy điện, việc dọn dẹp phòng khách có thể xem như nhiệm vụ nhẹ nhàng với Spot. Tuy nhiên, video gần đây về robot này nhặt giày dép và lon nước ngọt trong một ngôi nhà dân dụng đã hé lộ tiềm năng ứng dụng của các mô hình AI trong lĩnh vực robot. Trong trường hợp này, mô hình ngôn ngữ-hình ảnh (Visual-Language Model – VLM) của Google Gemini Robotics-ER 1.5 đã nâng cao khả năng lập luận thể hiện trí tuệ cho Spot.
Demo này được phát triển từ một hackathon năm 2025 tại Boston Dynamics, dựa trên các dự án trước đó sử dụng Mô hình Ngôn ngữ Lớn (LLMs) và Mô hình Nền tảng Hình ảnh (VFMs) để cho phép Spot nhận biết bối cảnh môi trường và thực hiện các hành động tự chủ phức tạp hơn so với nhiệm vụ Autowalk thông thường. Thay vì viết logic phần mềm cố định hay chương trình “trạng thái” định nghĩa từng bước cho một nhiệm vụ, chúng tôi tương tác với Gemini Robotics thông qua ngôn ngữ giao tiếp tự nhiên. Từ đó, Gemini Robotics đại diện để giao tiếp với Spot.
Bộ SDK Mạnh Mẽ và Hướng Dẫn Ngôn Ngữ Tự Nhiên Tiết Kiệm Thời Gian
Sử dụng SDK của Spot, chúng tôi phát triển một lớp trung gian hỗ trợ tương tác giữa Gemini Robotics và giao diện lập trình ứng dụng (API) của Spot. API này thường cung cấp cho các nhà phát triển quyền truy cập vào các khả năng của robot để xây dựng các ứng dụng hoặc hành vi tùy chỉnh. Ví dụ, các nhà nghiên cứu tại Meta đã sử dụng Spot để thử nghiệm hệ thống AI có khả năng định vị và lấy các vật thể mà nó chưa từng tiếp xúc trước đó.
Khả năng tương tác với Gemini Robotics qua các hướng dẫn ngôn ngữ tự nhiên giúp tiết kiệm đáng kể thời gian so với phương pháp lập trình truyền thống. Chúng tôi thông báo cho Gemini Robotics rằng nó có quyền điều khiển một robot di động được trang bị camera và cánh tay robot, cùng một bộ công cụ giới hạn để thực hiện các lệnh điều khiển robot. Mỗi công cụ là một đoạn mã nhỏ thực hiện các logic nội bộ và chuyển đổi các chỉ định từ Gemini Robotics thành các lệnh API thực tế. Các hành động được giới hạn vào việc di chuyển giữa các vị trí, chụp ảnh, nhận dạng vật thể, cầm nắm và đặt vật thể ở vị trí khác.
Phạm vi rộng của SDK cho phép phát triển một cách dễ dàng các ví dụ mở rộng quyền truy cập API mà yêu cầu rất ít công đoạn phát triển thêm.
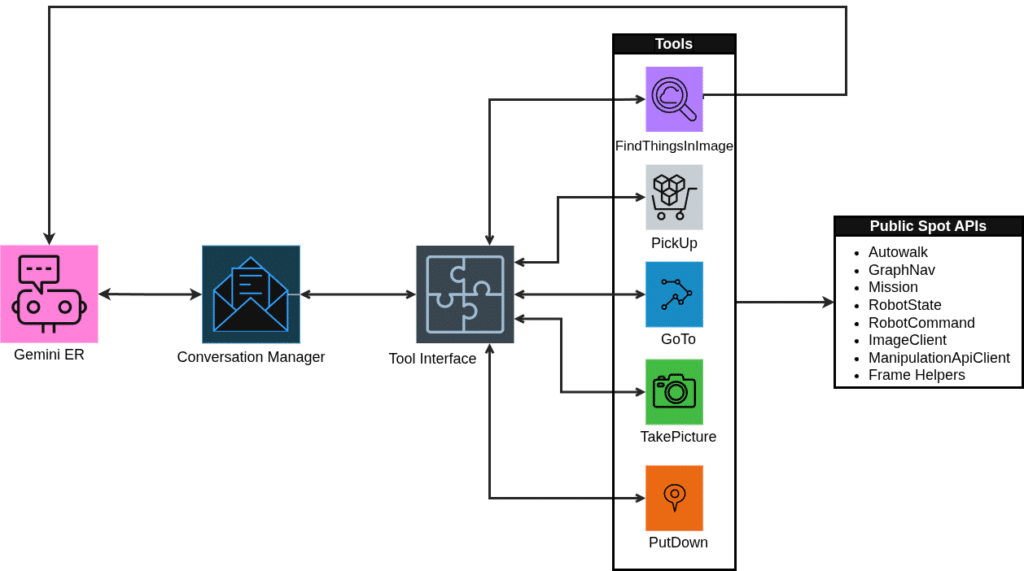
Thiết Lập Cơ Sở Cho Gemini Robotics
Chúng tôi bắt đầu bằng cách giải thích cho Gemini Robotics những nhiệm vụ cần thực hiện. Quá trình này gặp một số thử thách ban đầu khi soạn các lệnh cơ bản. Các chỉ dẫn đơn giản như “đặt vật thể xuống” hay “chụp ảnh” không đủ chi tiết để robot hành xử như mong muốn. Điều này yêu cầu chúng tôi thêm ngữ cảnh chính xác vào mỗi mô tả trong quá trình tối ưu công cụ.
Ví dụ điển hình là đoạn hướng dẫn chi tiết cho công cụ “TakePicture”:
Lệnh này sẽ khiến robot chụp ảnh bằng camera được chỉ định. Việc lựa chọn camera phù hợp có những điểm cần lưu ý. Khi đến một vị trí bằng lệnh GoTo, bạn nên bắt đầu chụp bằng camera ở cánh tay robot vì đây là camera cung cấp nhiều thông tin nhất.
Nếu robot đã đến vị trí và đang cầm vật thể, bạn có thể:
1. Gọi ngay lệnh PutDown
2. Quét khu vực bằng một trong các camera phía trước. Các camera phía trước thấp sát mặt đất, vì vậy nếu bạn muốn đặt vật trên bề mặt cao, chúng sẽ không cung cấp thông tin hữu ích.Ở ví dụ này, chúng tôi không cần mô tả chi tiết về cấu tạo khung hay cánh tay robot mà chỉ thông báo rằng camera phía trước của Spot sẽ không phù hợp để chụp các vật trên bề mặt cao. Qua đó, chúng tôi có thể nhanh chóng hiệu chỉnh nhờ các thay đổi nhỏ trong cách diễn đạt, mang lại kết quả tốt hơn rõ rệt. Khi đã có bộ công cụ cơ bản qua API, Gemini Robotics có thể sắp xếp các thao tác của Spot theo trình tự và thực hiện theo hướng dẫn được viết trên bảng trắng trong ngày trình diễn.
Cách Gemini Robotics và Spot Hợp Tác
Cho đến khi robot được kích hoạt, Gemini Robotics vẫn chưa có bối cảnh về những nhiệm vụ cụ thể mà robot sẽ thực hiện trong buổi demo. Chỉ với những chỉ dẫn đơn giản như, “Đảm bảo tất cả giày dép ở cửa trước đã được đặt lên kệ,” Gemini Robotics đã phân tích hình ảnh từ camera của Spot và xác định các đối tượng phù hợp với chỉ dẫn, từ đó làm mốc tham chiếu cho hệ thống định vị và thao tác của Spot.
Ở nhiều khía cạnh, Gemini Robotics hoạt động tương tự như một người điều khiển robot thủ công qua máy tính bảng. Ví dụ, để nhặt một vật thể, người vận hành sẽ di chuyển robot gần đến vật đó và dùng hướng dẫn cầm nắm để xác định vật cần lấy. Người điều khiển chỉ việc đưa ra chỉ đạo cấp cao, còn Spot sẽ xử lý các chi tiết thực thi. Trong demo, Gemini Robotics đóng vai trò vừa là người điều khiển vừa là giao diện gửi lệnh, giúp chúng tôi trở thành người lãnh đạo nhóm, chỉ cần cung cấp danh sách công việc và tin tưởng Spot cùng Gemini Robotics sẽ thực hiện phần còn lại.
Mô Hình Gọi và Phản Hồi
Khi Gemini Robotics kích hoạt một công cụ nào đó, công cụ sẽ trả về kết quả và ngữ cảnh, ví dụ như “Tôi đã nhặt được vật thể” hoặc “Tôi không thể cầm thêm vật khi tay đang đầy.” Gemini Robotics dựa trên phản hồi này để điều chỉnh kịp thời các lệnh cho Spot. Chẳng hạn, khi nhặt giày, Gemini Robotics yêu cầu hình ảnh, xác định vị trí giày và gửi lệnh “pickup”. Bằng việc xây dựng tập hợp công cụ cơ bản có khả năng liên kết ngữ nghĩa trong cuộc hội thoại, Gemini Robotics xử lý chuỗi nhiệm vụ để hoàn tất việc dọn phòng. Các phần mềm hiện tại của Spot quản lý bộ phận di chuyển, định vị và thao tác robot.
Điều quan trọng là Gemini Robotics hoạt động trong giới hạn nghiêm ngặt. Nó không thể sáng tạo ra năng lực mới hay điều khiển Spot vượt quá phạm vi API. Điều này đảm bảo hành vi của Spot luôn ổn định, đồng thời cho phép Gemini Robotics linh hoạt ứng phó với các tình huống đa dạng.
Một Công Cụ Tăng Cường Sức Mạnh Cho Nhà Phát Triển
Đối với các nhà phát triển đã làm việc với Spot, nghiên cứu này mở ra tiềm năng lớn. Qua SDK của Spot, họ tiếp cận được bộ công cụ mạnh mẽ của robot. Hiện nay, các doanh nghiệp sử dụng công cụ này để xây dựng ứng dụng trong kiểm tra, nghiên cứu và phân tích dữ liệu công nghiệp, v.v.
Mô hình AI như Gemini Robotics cung cấp phương thức mở rộng ứng dụng nhanh hơn. Thay vì viết hàng loạt logic nhiệm vụ trên API của Spot, nhà phát triển có thể thử nghiệm hệ thống AI hiểu các chỉ dẫn ngôn ngữ tự nhiên và linh hoạt điều khiển robot. Do đó, các mô hình như Gemini Robotics đóng vai trò như công cụ tăng cường sức mạnh, khuếch đại bộ công cụ vững chắc và hiệu suất ổn định vốn đã mang lại giá trị cho khách hàng Boston Dynamics.
Dự Đoán Tokken Tiếp Theo Cho Spot và Gemini Robotics
Mặc dù đây vẫn là bước thí nghiệm và chưa tạo ra ứng dụng hoàn chỉnh, nó minh họa một hướng đi đầy tiềm năng cho robot và AI vật lý. Các robot như Spot đã rất thành thục trong việc di chuyển trong môi trường phức tạp và thay đổi, thu thập dữ liệu và cảm biến cũng như thao tác vật thể. Thay vì phát minh lại từ đầu, các mô hình nền tảng AI mang đến cách tiếp cận mới để mở rộng những khả năng này tới nhiều bối cảnh và ứng dụng hơn.
AI vật lý là lĩnh vực phát triển nhanh, và đội ngũ của chúng tôi đang dẫn đầu cả trong phòng thí nghiệm và ứng dụng thực tiễn các robot được trang bị AI. Mặc dù mới bắt đầu trong quan hệ đối tác chính thức với Google Deepmind, chúng tôi rất lạc quan về tương lai với Atlas và đã triển khai các cải tiến thiết thực cho Spot và Orbit, điển hình là AIVI-Learning được hỗ trợ bởi Google Gemini Robotics ER 1.6. Phiên bản tiếp theo của công cụ kiểm tra hình ảnh AI này mở ra cấp độ thông minh hình ảnh mới, khi người dùng được hưởng lợi từ chuyên môn chia sẻ với trí tuệ ngữ cảnh sâu sắc hơn cho Spot và Orbit. Các cải tiến mô hình được tự động áp dụng phía sau, bổ sung thêm nhiều năng lực cho phần mềm và phần cứng hiện tại.
Demo ngày hôm nay hướng tới tương lai nơi người dùng dựa vào ngôn ngữ tự nhiên để hướng dẫn các hành động của Spot thay vì dựa vào mã phức tạp. Vai trò của kỹ sư sẽ chuyển thành việc thiết lập mục tiêu và nhiệm vụ, trong khi mô hình nền tảng đa phương thức trên robot giải thích hướng dẫn và xây dựng các kế hoạch phức tạp, linh hoạt; Spot sẽ thực thi chính xác các hành động đó.
Bài viết được đóng góp bởi Issac Ross và Nikhil Devraj, kỹ sư trong nhóm phát triển Spot.